导读
首先问大家一个小问题?区块链的账本数据存储格式主要是什么类型的?
相信聪明的你一定知道是Key-Value类型存储。
下一个问题,这些Key-Value数据在底层数据库如何高效组织?
答案就是我们本期介绍的内容:LSM。
LSM是一种被广泛采用的持久化Key-Value存储方案,如LevelDB,RocksDB,Cassandra等数据库均采用LSM作为其底层存储引擎。
据公开数据调研,LSM是当前市面上写密集应用的最佳解决方案,也是区块链领域被应用最多的一种存储模式,今天我们将对LSM基本概念和性能进行介绍和分析。
LSM-Tree背景:追本溯源
LSM-Tree的设计思想来自于一个计算机领域一个老生常谈的话题——对存储介质的顺序操作效率远高于随机操作。
如图1所示,对磁盘的顺序操作甚至可以快过对内存的随机操作,而对同一类磁盘,其顺序操作的速度比随机操作高出三个数量级以上,因此我们可以得出一个非常直观的结论:应当充分利用顺序读写而尽可能避免随机读写。
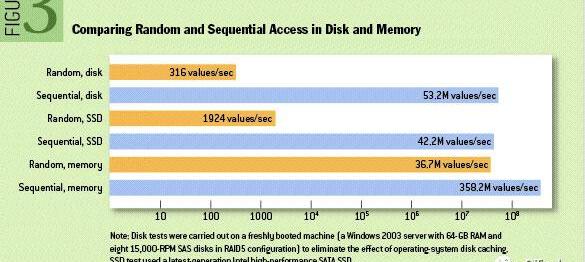
Figure1Randomaccessvs.Sequentialaccess
国家标准《区块链和分布式记账技术 参考架构》于5月23日获批发布:金色财经报道,国家标准GB/T 42752-2023《区块链和分布式记账技术 参考架构》于5月23日获批发布。国家标准《区块链和分布式记账技术 参考架构》由TC590(全国区块链和分布式记账技术标准化技术委员会)归口,主管部门为工业和信息化部。主要起草单位包括中国电子技术标准化研究院、中国人民银行数字货币研究所、上海万向区块链股份公司等;主要起草人包括周平、穆长春、李鸣等。
据全国标准信息公共服务平台,《区块链和分布式记账技术 参考架构》于2023年5月23日发布,将于2023年12月1日实施。[2023/5/26 9:44:28]
考虑到这一点,如果我们想尽可能提高写操作的吞吐量,那么最好的方法一定是不断地将数据追加到文件末尾,该方法可将写入吞吐量提高至磁盘的理论水平,然而也有显而易见的弊端,即读效率极低,我们称这种数据更新是非原地的,与之相对的是原地更新。
为了提高读取效率,一种常用的方法是增加索引信息,如B+树,ISAM等,对这类数据结构进行数据的更新是原地进行的,这将不可避免地引入随机IO。
LSM-Tree与传统多叉树的数据组织形式完全不同,可以认为LSM-Tree是完全以磁盘为中心的一种数据结构,其只需要少量的内存来提升效率,而可以尽可能地通过上文提到的Journaling方式来提高写入吞吐量。当然,其读取效率会稍逊于B+树。
动态 | 蚂蚁金服致力于区块链技术 连接消费者和小微企业:据新华网报道,近日第五届世界互联网大会在浙江乌镇举办,15项来自中、美、英等国的科技成果成功发布。其中蚂蚁金服则是用区块链技术连接消费者和小微企业,解决他们的实际问题。今年6月,蚂蚁区块链的跨境汇款从香港支付宝到菲律宾的GCash钱包正式打通上线,收款时间和手续费都大幅度降低,更加便捷、安全、透明,实现了供应链中应收账款的高效可信流转,帮助供应链上的小微企业以更低成本获得融资。[2018/11/12]
LSM-Tree数据结构:抽丝剥茧
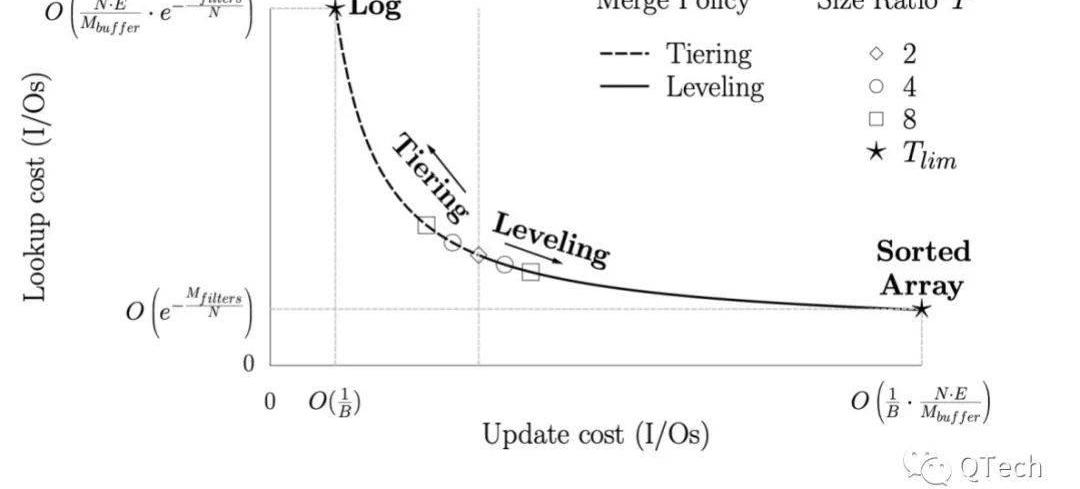
图2展示了LSM-Tree的理论模型(a)和一种实现方式(b)。LSM-Tree是一种层级的数据结构,包含一层空间占用较小的内存结构以及多层磁盘结构,每一层磁盘结构的空间上限呈指数增长,如在LevelDB中该系数默认为10。
Figure2LSM与其LevelDB实现
对于LSM-Tree的数据插入或更新,首先会被缓存在内存中,这部分数据往往由一颗排序树进行组织。
当缓存达到预设上限,则会将内存中的数据以有序的方式写入磁盘,我们称这样的有序列为一个SortedRun,简称为Run。
随着写入操作的不断进行,L0层会堆积越来越多的Run,且显然不同的Run之前可能存在重叠部分,此时进行某一条数据的查询将无法准确判断该数据存在于哪个Run中,因此最坏情况下需要进行等同于L0层Run数量的I/O。
为了解决该问题,当某一层的Run数目或大小到达某一阈值后,LSM-Tree会进行后台的归并排序,并将排序结果输出至下一层,我们将一次归并排序称为Compaction。如同B+树的分裂一样,Compaction是LSM-Tree维持相对稳定读写效率的核心机制,我们将会在下文详细介绍两种不同的Compaction策略。
动态 | 佳沃股份:拟在海产品领域引入区块链技术 :佳沃股份董事会秘书崔志勇在活动中表示,公司已经与专业机构慧聪集团签署合作协议,拟在海产品领域引入区块链技术,通过现代农业产业链应用平台建设,解决未来交易中的信用问题。[2018/9/11]
另外值得一提的是,无论是从内存到磁盘的写入,还是磁盘中不断进行的Compaction,都是对磁盘的顺序I/O,这就是LSM拥有更高写入吞吐量的原因。
Levelingvs.Tiering:一读一写,不分伯仲
LSM-Tree的Compaction策略可以分为Leveling和Tiering两种,前者被LevelDB,RocksDB等采用,后者被Cassandra等采用,称采用Leveling策略的的LSM-Tree为LeveledLSM-Tree,采用Tiering的LSM-Tree为TieredLSM-Tree,如图3所示。
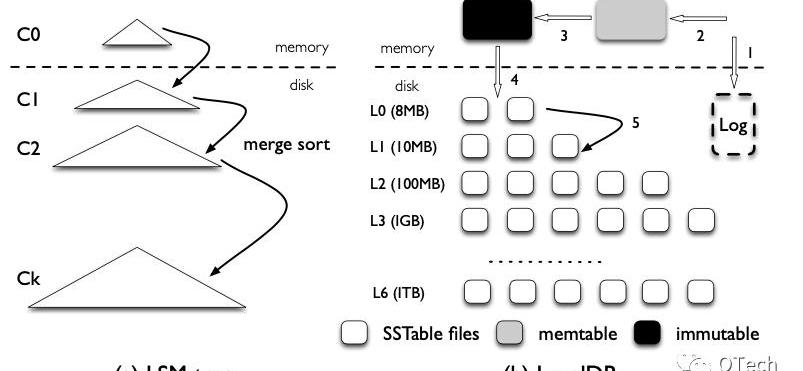
Figure3两种Compaction策略对比
▲Leveling
简而言之,Tiering是写友好型的策略,而Leveling是读友好型的策略。在Leveling中,除了L0的每一层最多只能有一个Run,如图3右侧所示,当在L0插入13时,触发了L0层的Compaction,此时会对Run-L0与下层Run-L1进行一次归并排序,归并结果写入L1,此时又触发了L1的Compaction,此时会对Run-L1与下层Run-L2进行归并排序,归并结果写入L2。
政策 | 浙江省利用区块链等技术 结合政府数字化转型打造智信社会:据浙江日报消息,浙江省社会科学院课题组发文称,要不断优化政府数字化转型推进机制,利用“区块链”等技术公开透明、可追踪不可篡改等特点深挖信用价值,结合政府数字化转型打造智信社会。按照物理分散、逻辑集中的模式,积极探索区块链、大数据等新兴技术在数据共享中的应用。加快推进政府数字化转型,打造省级数字政府样板,为国家实施数字政府建设积累经验。[2018/9/4]
▲Tiering
反观Tiering在进行Compaction时并不会主动与下层的Run进行归并,而只会对发生Compaction的那一层的若干个Run进行归并排序,这也是Tiering的一层会存在多个Run的原因。
▲对比分析
相比而言,Leveling方式进行得更加贪婪,进行了更多的磁盘I/O,维持了更高的读效率,而Tiering则相正好反。
本节我们将对LSM-Tree的设计空间进行更加形式化的分析。
LSM层数

布隆过滤器
LSM-Tree应用布隆过滤器来加速查找,LSM-Tree为每个Run设置一个布隆过滤器,在通过I/O查询某个Run之前,首先通过布隆过滤器判断待查询的数据是否存在于该Run,若布隆过滤器返回Negative,则可断言不存在,直接跳到下个Run进行查询,从而节省了一次I/O;而若布隆过滤器返回Positive,则仍不能确定数据是否存在,需要消耗一次I/O去查询该Run,若成功查询到数据,则终止查找,否则继续查找下一个Run,我们称后者为假阳现象,布隆过滤器的过高的假阳率会严重影响读性能,使得花费在布隆过滤器上的内存形同虚设。限于篇幅本文不对布隆过滤器做更多的介绍,直接给出FPR的计算公式,为公式2.
日本电气NEC开发出全球最快区块链技术 每秒交易可超10万笔:据中国科技网今日报道,日本电气股份有限公司(NEC)及NEC欧洲研究所开发了全球最快的区块链共识算法,可以在参与交易的节点数达到200个左右的大规模连接环境下,达到每秒处理10万笔以上交易的超高记录性能。作为一个支撑信用卡在世界范围内进行交易的系统,每秒处理性能必须达到几万笔以上,这项技术促进了这种性能的实现,也加速了区块链在商务领域中的真正应用。[2018/3/12]
其中是为布隆过滤器设置的内存大小,为每个Run中的数据总数。读写I/O
考虑读写操作的最坏场景,对于读操作,认为其最坏场景是空读,即遍历每一层的每个Run,最后发现所读数据并不存在;对于写操作,认为其最坏场景是一条数据的写入会导致每一层发生一次Compaction。
核心理念:基于场景化的设计空间
基于以上分析,我们可以得出如图4所示的LSM-Tree可基于场景化的设计空间。
简而言之,LSM-Tree的设计空间是:在极端优化写的日志方式与极端优化读的有序列表方式之间的折中,折中策略取决于场景,折中方式可以对以下参数进行调整:

当Level间放大比例时,两种Compaction策略的读写开销是一致的,而随着T的不断增加,Leveling和Tiering方式的读开销分别提高/减少。
当T达到上限时,前者只有一层,且一层中只有一个Run,因此其读开销到达最低,即最坏情况下只需要一次I/O,而每次写入都会触发整层的Compaction;
而对于后者当T到达上限时,也只有一层,但是一层中存在:

因此读开销达到最高,而写操作不会触发任何的Compaction,因此写开销达到最低。
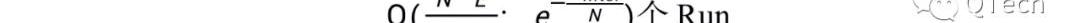
Figure4LSM由日志到有序列的设计空间
事实上,基于图4及上文的分析可以进行对LSM-Tree的性能进一步的优化,如文献对每一层的布隆过滤器大小进行动态调整,以充分优化内存分配并降低FPR来提高读取效率;文献提出“LazyLeveling”方式来自适应的选择Compaction策略等。
限于篇幅本文不再对这些优化思路进行介绍,感兴趣的读者可以自行查阅文献。
小结
LSM-Tree提供了相当高的写性能、空间利用率以及非常灵活的配置项可供调优,其仍然是适合区块链应用的最佳存储引擎之一。
本文对LSM-Tree从设计思想、数据结构、两种Compaction策略几个角度进行了由浅入深地介绍,限于篇幅,基于本文之上的对LSM-Tree的调优方法将会在后续文章中介绍。
作者简介叶晨宇来自趣链科技基础平台部,区块链账本存储研究小组
参考文献
.O’NeilP,ChengE,GawlickD,etal.Thelog-structuredmerge-tree(LSM-tree).ActaInformatica,1996,33(4):351-385.
.JacobsA.Thepathologiesofbigdata.CommunicationsoftheACM,2009,52(8):36-44.
.LuL,PillaiTS,GopalakrishnanH,etal.Wisckey:Separatingkeysfromvaluesinssd-consciousstorage.ACMTransactionsonStorage(TOS),2017,13(1):1-28.
.DayanN,AthanassoulisM,IdreosS.Monkey:Optimalnavigablekey-valuestore//Proceedingsofthe2017ACMInternationalConferenceonManagementofData.2017:79-94.
.DayanN,IdreosS.Dostoevsky:Betterspace-timetrade-offsforLSM-treebasedkey-valuestoresviaadaptiveremovalofsuperfluousmerging//Proceedingsofthe2018InternationalConferenceonManagementofData.2018:505-520.
.LuoC,CareyMJ.LSM-basedstoragetechniques:asurvey.TheVLDBJournal,2020,29(1):393-418.
本报记者?邢?萌 蚂蚁S9矿机被比特币挖矿圈公认为“一代机皇”。2016年比特币第二次减半前夕,这台由比特大陆自主研发的比特币矿机,一经推出即遭市场抢购,每台售价一度被炒高到2万多元.
1900/1/1 0:00:00在一次DeFi峰会的发言中,CompoundFinance创始人RobertLeshner相信CeFi将拥抱DeFi.
1900/1/1 0:00:00社交网络的发达拉近了我们每个人的距离,也让我们每个人都有权利表达自己的观点,每个人都可以成为一名内容创作者,每个人也都会或多或少地拥有自己的粉丝.
1900/1/1 0:00:00来源:财联社 作者:周玲 财联社讯,受益于20余年来最湿润的天气,北欧地区水力发电厂今年的发电量大增,使瑞典和挪威的电力价格处于世界最低水平。由于电价暴跌,北欧地区比特币挖矿活动的利润今年激增了两倍。2020年,比特币价格大涨近两倍.
1900/1/1 0:00:00整理:SoonaAmhaz,TokenDaily联合创始人,VoltCapital普通合伙人 翻译:卢江飞 又到了一年结束的时候,和往年一样,现在是时候让TokenDaily为大家打开2021年的水晶球了!今年.
1900/1/1 0:00:00?Coinbase申请IPO的消息传出后不久,美国证券交易委员会找上了瑞波的麻烦,指控后者通过发行未经注册的数字资产证券筹集巨量资金。两件乍看风马牛不相及的事,触动了Coinbase的警觉神经.
1900/1/1 0:00:00