作者:@於方仁/img/20230515155829573550/0.jpg "/>
目前生态上讲,BERT多用于微调场景。因为微调必须在开源模型的基础上,GPT仅开源到GPT2的系列。且相同模型参数量下BERT在特定场景的效果往往高于GPT,微调需要调整全部的模型参数,所以从性价比而言,BERT比GPT更适合微调。
而GPT目前拥有ChatGPT这种面向广大人民群众的应用,使用简单。API的调用也尤其方便。所以若是仅使用LLM,则ChatGPT显然更有优势。
ChatGPTPrompt
下图是OpenAI官方提出对于ChatGPT的prompt用法大类。
Base针对合约开发者推出Base Builder Quest:金色财经报道,Coinbase以太坊Layer2网络Base针对智能合约开发者推出Base Builder Quest,允许开发者在Base上部署智能合约来完成任务,成为早期的Base构建者。Base还将为完成任务的开发者分发由andreoshea.eth设计的纪念NFT,在过渡到Base主网后,开发者还将有资格铸造第二个纪念NFT。[2023/4/7 13:49:45]

Figure1.PromptCategoriesbyOpenAI?
每种类别有很多具体的范例。如下图所示:
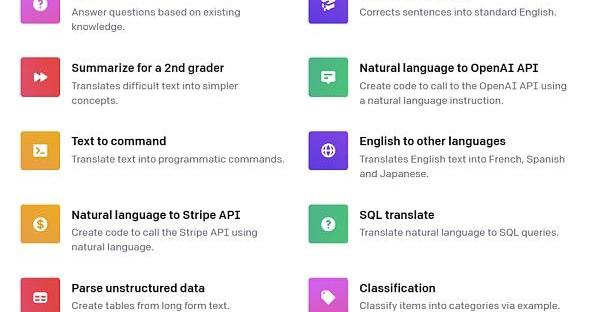
Figure2.PromptCategoriesExamplesbyOpenAI
除此以外,我们在此提出一些略微高级的用法。
高级分类
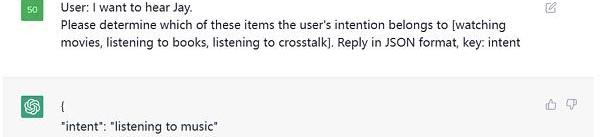
这是一个意图识别的例子,本质上也是分类任务,我们指定了类别,让ChatGPT判断用户的意图在这
Sui宣布Builder House越南站获胜团队:3月20日消息,Layer1公链Sui Network宣布Builder House越南站获胜团队,多链NFT市场Mynft团队获得第一名,收益协议Typus Finance团队获得第二名,随机利率协议Scallop和SocialFi应用程序ComingChat团队获得第三名。据悉,SuiBuilder Houses提供与全球Sui构建者会面和合作的机会。2023年Sui计划在12个地方举行Builder Houses,越南站是第二站,下一站将于4月14日至4月16日在香港举办。[2023/3/20 13:14:04]
Figure3.PromptExamples
实体识别与关系抽取
利用ChatGPT做实体识别与关系抽取轻而易举,例如给定一篇文本后,这么像它提问。
Figure4.ExampleTextGiventoChatGPT
这是部分结果截图:
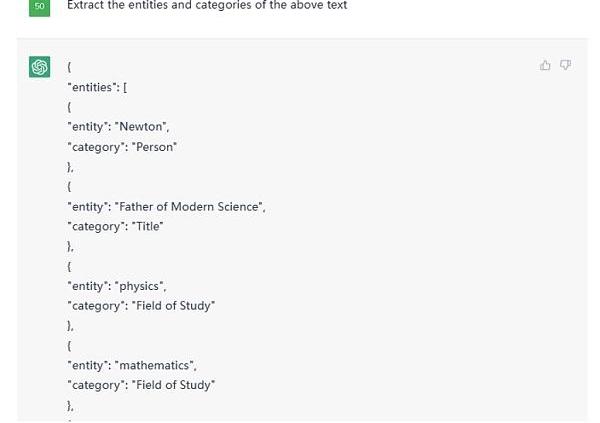
Figure5.PartialOutputfromgivenTextonChatGPT
之后可以追问给他们的关系,例如:

MEV运营商Flashbots宣布开源Flashbots Builder:11月20日消息,MEV运营商Flashbots宣布开源Flashbots Builder,旨在帮助以太坊生态系统进一步发展,目前源代码已经发布在GitHub上。
Flashbots表示,利用其最新构建的完全去中心化区块构建器新版本SUAVE,每个构建者都能成为区块贡献的一份子,而不会让某个单一实体构建整个区块。[2022/11/21 7:50:35]
Figure6.AskingrelationshiponChatGPT
这样,一个大型的知识图谱便可轻松建立。
分析任务
如下图所示,我对ChatGPT提出了分析我目前需求的问题。
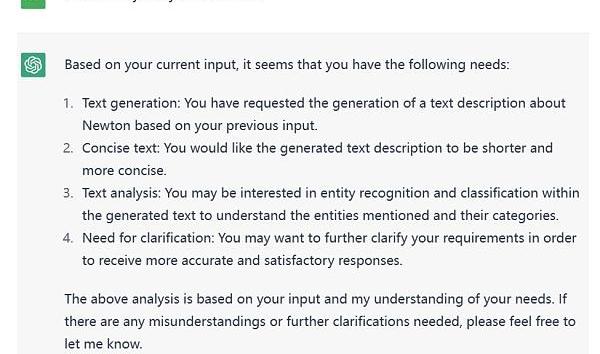
Figure7.ResultforneedsrequestonChatGPT
甚至还能让它给定分数。

Figure8.Scoringtoevaluatetheidentifiedneeds
除此以外还有数不胜数的方式,在此不一一列举。
组合Agent
另外,我们在使用ChatGPT的API时,可以将不同的prompt模板产生多次调用产生组合使用的效果。我愿称这种使用方式叫做,组合Agent。例如Figure1展示的是一个大概的思路。
Axie Infinity推出Builders Program计划,旨在进一步提升游戏体验:1月21日消息,P2E游戏Axie Infinity官方宣布推出Builders Program,并提供总计5000枚AXS支持该计划,旨在为社区开发者提供资源、推广、支持和工具以进一步提升Axie Infinity的游戏体验。据Axie Infinity透露,凡是入选的项目至少可以获得价值5000美元的AXS捐赠,还能得到SkyMavis游戏设计和产品的指导,以及Ronin Network测试网、SSO和钱包集成等支持。[2022/1/22 9:05:16]
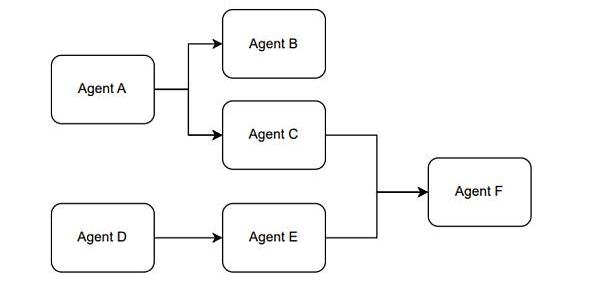
Figure9.?TheParadigmoftheCombinationAgent
具体说来,例如是一个辅助创作文章的产品。则可以这么设计,如Figure10所示。
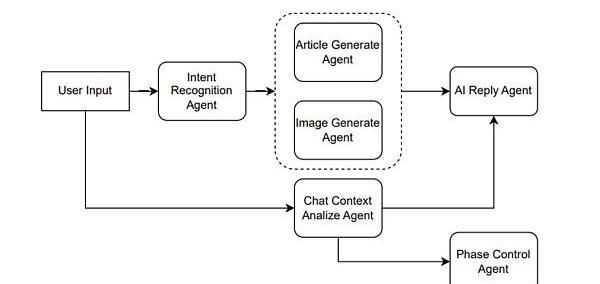
Figure10.Agentcombinationforassistingincreation
假设用户输入一个请求,说“帮我写一篇伦敦游记”,那么IntentRecognitionAgent首先做一个意图识别,意图识别也就是利用ChatGPT做一次分类任务。假设识别出用户的意图是文章生成,则接着调用ArticleGenerateAgent。
HCL Technologies与R3合作推出区块链平台BUILDINGBLOCK:HCL Technologies与R3合作推出区块链平台BUILDINGBLOCK,旨在简化跨国公司的商业财产保险。(Fstech)[2020/8/18]
另一方面,用户当前的输入与历史的输入可以组成一个上下文,输入给ChatContextAnalyzeAgent。当前例子中,这个agent分析出的结果传入后面的AIReplyAgent和PhaseControlAgent的。
AIReplyAgent就是用来生成AI回复用户的语句,假设我们的产品前端并不只有一个文章,另一个敌方还有一个框用来显示AI引导用户创作文章的语句,则这个AIReplyAgent就是用来干这个事情。将上下文的分析与文章一同提交给ChatGPT,让其根据分析结果结合文章生成一个合适的回复。例如通过分析发现用户只是在通过聊天调整文章内容,而不知道AI还能控制文章的艺术意境,则可以回复用户你可以尝试着对我说“调整文章的艺术意境为非现实主义风格”。
PhaseControlAgent则是用来管理用户的阶段,对于ChatGPT而言也可以是一个分类任务,例如阶段分为等等。例如AI判断可以进行文章模板的制作了,前端可以产生几个模板选择的按钮。
使用不同的Agent来处理用户输入的不同任务,包括意图识别、ChatContext分析、AI回复生成和阶段控制,从而协同工作,为用户生成一篇伦敦游记的文章,提供不同方面的帮助和引导,例如调整文章的艺术意境、选择文章模板等。这样可以通过多个Agent的协作,使用户获得更加个性化和满意的文章生成体验。?
Prompt微调
LLM虽然很厉害,但离统治人类的AI还相差甚远。眼下有个最直观的痛点就是LLM的模型参数太多,基于LLM的模型微调变得成本巨大。例如GPT-3模型的参数量级达到了175Billion,只有行业大头才有这种财力可以微调LLM模型,对于小而精的公司而言该怎么办呢。无需担心,算法科学家们为我们创新了一个叫做prompttuning的概念。
Prompttuning简单理解就是针对prompt进行微调操作,区别于传统的fine-tuning,优势在于更快捷,prompttuning仅需微调prompt相关的参数从而去逼近fine-tuning的效果。

Figure11.Promptlearning
什么是prompt相关的参数,如图所示,prompttuning是将prompt从一些的自然语言文本设定成了由数字组成的序列向量。本身AI也会将文本从预训练模型中提取向量从而进行后续的计算,只是在模型迭代过程中,这些向量并不会跟着迭代,因为这些向量于文本绑定住了。但是后来发现这些向量即便跟着迭代也无妨,虽然对于人类而言这些向量迭代更新后在物理世界已经找不到对应的自然语言文本可以表述出意思。但对于AI来讲,文本反而无意义,prompt向量随着训练会将prompt变得越来越符合业务场景。
假设一句prompt由20个单词组成,按照GPT3的设定每个单词映射的向量维度是12288,20个单词便是245760,理论上需要训练的参数只有245760个,相比175billion的量级,245760这个数字可以忽略不计,当然也会增加一些额外的辅助参数,但同样其数量也可忽略不计。
问题来了,这么少的参数真的能逼近?finetuning的效果吗,当然还是有一定的局限性。如下图所示,蓝色部分代表初版的prompttuning,可以发现prompttuning仅有在模型参数量级达到一定程度是才有效果。虽然这可以解决大多数的场景,但在某些具体垂直领域的应用场景下则未必有用。因为垂直领域的微调往往不需要综合的LLM预训练模型,仅需垂直领域的LLM模型即可,但是相对的,模型参数不会那么大。所以随着发展,改版后的prompttuning效果可以完全取代fine-tuning。下图中的黄色部分展示的就是prompttuningv2也就是第二版本的prompttuning的效果。
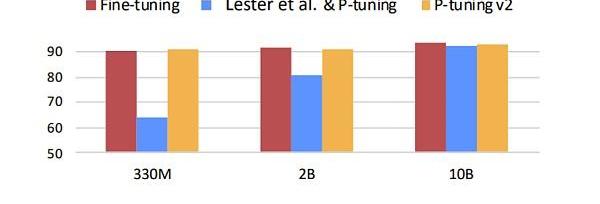
Figure12.Promptlearningparameters
V2的改进是将原本仅在最初层输入的连续prompt向量,改为在模型传递时每一个神经网络层前均输入连续prompt向量,如下图所示。

Figure13.Promptlearningv2
还是以GPT3模型为例,GPT3总从有96层网络,假设prompt由20个单词组成,每个单词映射的向量维度是12288,则所需要训练的参数量=96*20*12288=23592960。是175billion的万分之1.35。这个数字虽不足以忽略不计,但相对而言也非常小。
未来可能会有prompttuningv3,v4等问世,甚至我们可以自己加一些创新改进prompttuning,例如加入长短期记忆网络的设定。(因为原版的prompttuningv2就像是一个大型的RNN,我们可以像改进RNN一般去改进prompttuningv2)。总之就目前而言,prompttuning使得微调LLM变得可行,未来一定会有很多垂直领域的优秀模型诞生。
总结
LargeLanguageModels(LLMs)和Web3技术的整合为去中心化金融领域带来了巨大的创新和发展机遇。通过利用LLMs的能力,应用程序可以对大量不同数据源进行全面分析,生成实时的投资机会警报,并根据用户输入和先前的交互提供定制建议。LLMs与区块链技术的结合还使得智能合约的创建成为可能,这些合约可以自主地执行交易并理解自然语言输入,从而促进无缝和高效的用户体验。
这种先进技术的融合有能力彻底改变DeFi领域,并开辟出一条为投资者、交易者和参与去中心化生态系统的个体提供新型解决方案的道路。随着Web3技术的日益普及,LLMs创造复杂且可靠解决方案的潜力也在扩大,这些解决方案提高了去中心化应用程序的功能和可用性。总之,LLMs与Web3技术的整合为DeFi领域提供了强大的工具集,提供了有深度的分析、个性化的建议和自动化的交易执行,为该领域的创新和改革提供了广泛的可能性。
参考文献

摘要:据阿尔法工场研究院报道,在今年爆发的AI大战中,微软、谷歌、亚马逊等各个大厂,都纷纷使出了自己的浑身解数,渴望在未来的赛道中抢占先机。然而,同样身为科技界龙头企业的苹果,却在这场竞争中“哑火”了.
1900/1/1 0:00:00来源:新智元 导读:Gen-1能在iPhone上用了,安卓版用户坐等上线。没想到,「视频版的Midjourney」已经上线APPStore了! 划重点,能够免费体验.
1900/1/1 0:00:00文: 新莓daybreak,作者:史圣园 图片来源:由无界AI工具生成「即日起,管理层决定无期限全面停止创意设计、方案撰写、文案撰写、短期雇员四类相关外包支出.
1900/1/1 0:00:00一、整体概述 DeFi?协议?CurveFinance?已在以太坊主网上部署其原生稳定币?crvUSD。由于?crvUSD?尚未集成到?Curve?的用户界面中,因此要等到?UI?部署完成后才能向公众开放.
1900/1/1 0:00:00博链财经BroadChain获悉,5月6日,Galaxy研究副总裁ChristineKim发文总结第108次以太坊核心开发者共识会议,开发人员在会上讨论和协调对以太坊共识层的更改.
1900/1/1 0:00:00将现实生活中的体验带入一个全新的维度,ERMLABS专注于将现实生活中的娱乐及冒险体验以游戏独特架构设计扩展到元宇宙里.
1900/1/1 0:00:00