本文主要来介绍NLP中的命名实体识别。命名实体识别与中文分词、词性标注一样,也是NLP的一个基础任务,是信息抽取、信息检索、机器翻译、问答系统等多种NLP技术不可或缺的一部分。其目的是:识别语料中的人名、地名、组织机构名等命名实体。
随着命名实体数量的不断增加,一般不可能在词典中全部列出,由于命名实体的构成方法具有规律性,通常把对这些词的识别在任务中进行独立处理,称之为命名实体识别。NER一般分为3大类和7小类。

1.中文命名实体识别的难点
各类命名实体的数量众多。命名实体的构成规律复杂。比如人名的构成规则各有不同,中文人名识别又可以细分为中国人名识别、日本人名识别和音译人名识别等;再比如机构名的组成方式,机构名的种类繁多,各有独特的命名方式,用词也相当广泛,只有结尾用词相对集中。嵌套情况复杂。一个命名实体经常和一些词组合成一个嵌套的命名实体,人名中嵌套着地名,地名中也经常嵌套着人名。长度不确定。与其他类型的命名实体相比,长度和边界难以确定,使得机构名更难识别。中国人名一般二到四字,常用地名一般二到四字,但是机构名长度变化范围极大,少的只有两个字简称,多的达到几十个字的全称。2命名实体识别方式
Sepolia测试网现在是Chainlink的主要以太坊测试网:金色财经报道,Chainlink在社交媒体上发文表示,Sepolia测试网现在是Chainlink的主要以太坊测试网,其核心服务如价格信息流、VRF、自动化和功能已经在网络上运行。开发者可以使用Chainlink水龙头访问Sepolia ETH和LINK。[2023/3/5 12:42:39]
中文分词中,主要有基于规则方法、基于统计方法和基于二者的混合方法。命名实体识别主要也包含这三种方法。
基于规则的命名实体识别:规则加词典是早期命名实体识别中最行之有效的方式。依赖手工规则,结合命名实体库,对每条规则进行权重赋值,然后通过实体与规则的相符情况来进行类型判断。基于统计的命名实体识别:与分词类似,目前主流的基于统计的命名实体识别方法有:隐马尔可夫模型、最大熵模型、条件随机场等。其主要思想是:基于人工标注的语料,将命名实体识别任务作为序列标注问题来解决。基于混合的命名实体识别:NLP并不完全是一个随机过程,单独使用基于统计的方法使状态搜索空间非常庞大,必须借助规则知识提前进行过滤修剪处理。目前几乎没有单纯使用统计模型而不使用规则知识的命名实体识别系统,在很多情况下是使用混合方法,结合规则和统计方法。序列标注方式是目前命名实体识别中的主流方法,下面重点介绍基于CRF条件随机场的方法。
NASDEX已集成Chainlink喂价:金色财经报道,据官方消息,NASDEX已在Polygon主网上集成了Chainlink喂价,以将亚洲股票安全、准确的价格数据带入NASDEX交易平台。NASDEX将使用Chainlink驱动的去中心化预言机对链上的合成资产进行定价,帮助减少铸造、交换和赎回过程中的滑点,并进一步确保公平清算。[2021/11/10 6:42:16]
3基于CRF的命名实体识别
条件随机场的主要思想来源于HMM,也是一种用来标记和切分序列化数据的统计模型。不同的是,条件随机场是在给定观察的标记序列下,计算整个标记序列的联合概率,而HMM是在给定当前状态下,定义下一个状态的分布。
条件随机场的定义为:假设X=(X1,X2,X3,…,Xn)和Y=(Y1,Y2,Y3,…,Ym)是联合随机变量,若随机变量Y构成一个无向图G=(V,E)表示的马尔可夫模型,则其条件概率分布P(Y|X)称为条件随机场,即:
多功能DeFi平台DEXKIT已在Polygon上集成Chainlink喂价:10月12日消息,多功能DeFi平台DEXKIT已在Polygon上集成Chainlink喂价,以结算其加密资产预测市场游戏Coin Leagues。同时,DEXKIT计划使用Chainlink Keepers以在预测市场时间段结束后,进行自动结算。[2021/10/12 20:23:16]
P(Yv|X,Yw,w≠v)=P(Yv|X,Yw,w~v)
其中w~v表示无向图G=(V,E)中与结点v有边连接的所有节点,w≠v表示结点v以外的所有节点。
例如:对句子“我来到陶家村”进行标注,正确标注后的结果为:我/O来/O到/O陶/B家/M村/E。采用线性链CRF来进行解决,那么是其一种标注序列,也是是其一种标注选择,类似的可选择的标注序列有很多,在NER任务中就是在这么多的可选标注序列中,找出最靠谱的作为句子的标注。
Gapless获550万欧元种子轮融资,FinLab EOS VC基金领投:柏林区块链初创公司Gapless获得550万欧元(合600万美元)的种子轮融资,由FinLab EOS VC基金领投。据悉,FinLab EOS VC基金是FinLab和Block.one的联合项目。Gapless正在打造其宣称的“全球第一个汽车管理区块链平台”。(Red Herring)[2020/4/29]
那么我们要解决的问题就是要判断标注序列是否靠谱。就刚才的两种标注方法,显然第一种比第二种更为准确,因为第二种将“陶”和“家”都作为地名首字标成了“B”,一个地名两个首字符,显然不合理。假如给每个标注序列打分,分值代表标注序列的靠谱程度,越高代表越靠谱,那么可以定一个规则,若在标注中出现连续两个“B”结构的标注序列,则给它低分。连续“B”结构打低分就对应一条特征函数。在CRF中,定义一个特征函数集合,然后使用这个特征函数集合为标注序列进行打分,据此选出最靠谱的标注序列,该序列的分值是通过特征函数集合得出的。
日本Innlovi公司建立区块链专业人才招聘网站,以解决业界人才短缺问题:日本Innlovi宣布,由该公司开发运营的区块链专业人才招聘网站“Blockchain Jobs”已于3月28日开放提前登陆。[2018/3/29]
在CRF中有两种特征函数,分别为:转移函数tk(yi-1,yi,i)和状态函数sl(yi,X,i)。tk(yi-1,yi,i)依赖于当前和前一个位置,表示从标注序列中位置i-1的标记yi-1转移到位置i上的标记yi的概率。sl(yi,X,i)依赖当前位置,表示标记序列在位置i上为标记yi的概率。通常特征函数取值为1或0,表示符不符合该条规则约束。
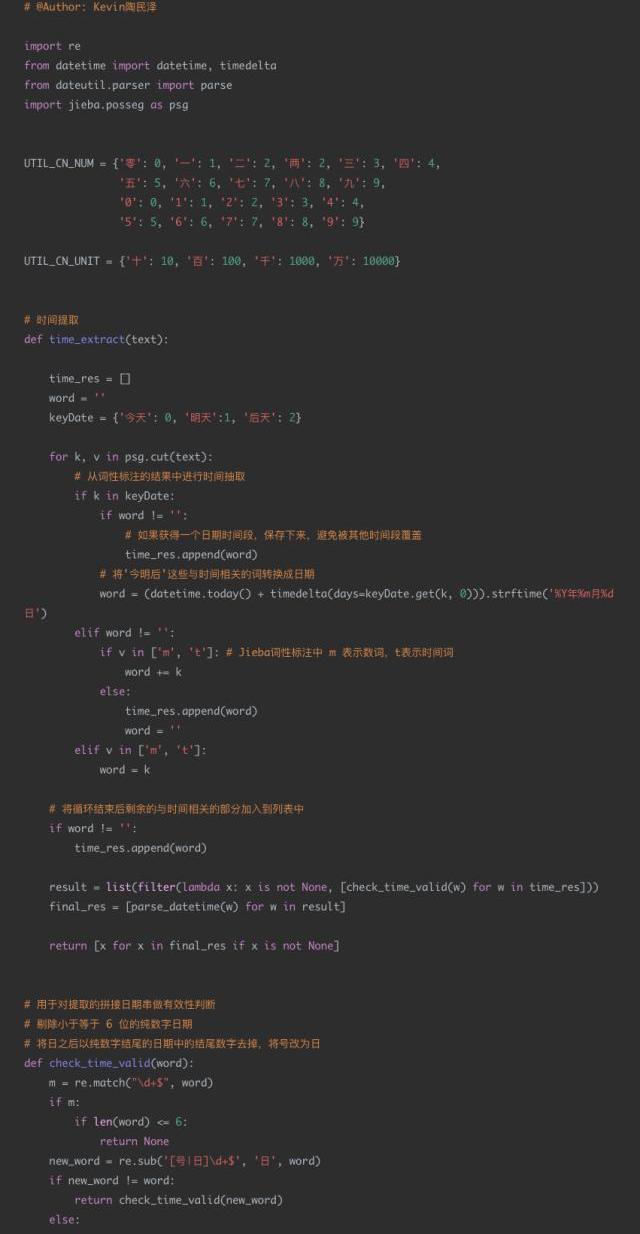
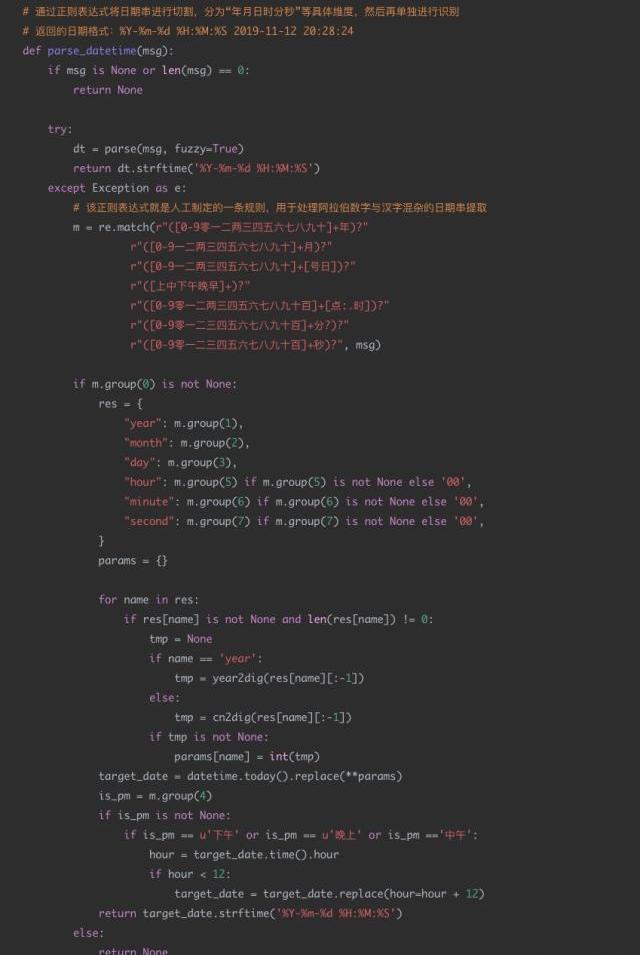
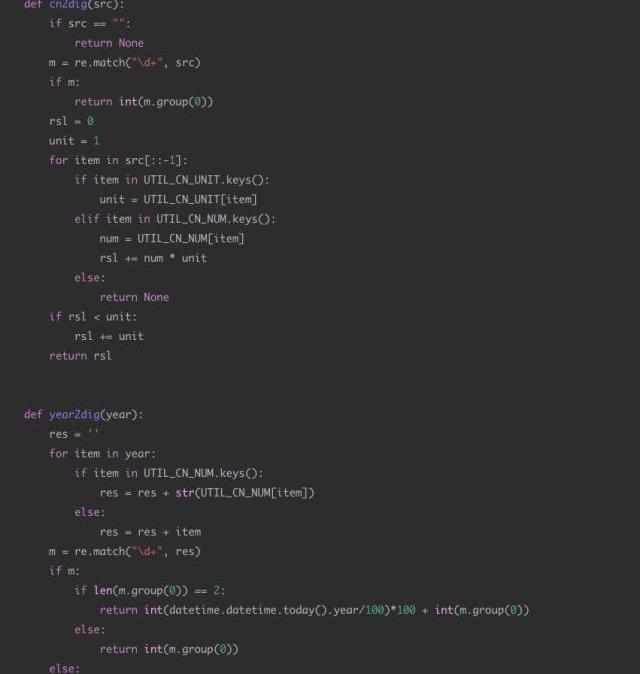
4日期识别代码示例
应用场景:
现有一个智能外呼系统,由机器人拨打电话给客户,通知客户新股中签情况,客户与机器人进行对话。对话机器人根据用户的语音进行解析,发觉用户的需求,比如:新股中签的时间,新股买入的时间等。通过asr技术将用户的语音转换成中文文本,然后由于asr的识别准确度问题,许多日期类的数据并不是严格的数字,比如会出现“十一月12日”“2019年11月”“20191112”“后天下午”等形式。
现在的需求是识别出每个请求文本中可能的日期信息,并将其转换成统一的格式进行输出。比如:“我打算今天或明天买入新股”,那么通过日期解析后,应该输出为“2019-11-12”和“2019-11-13”。
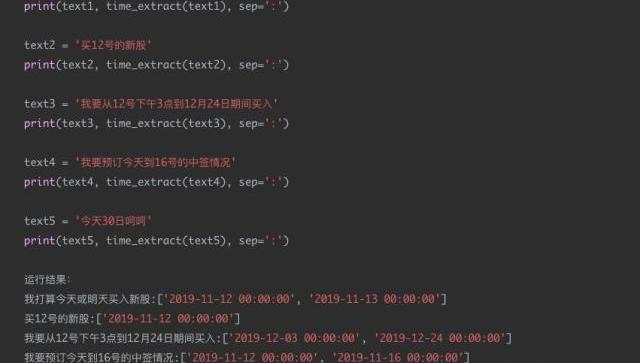
通过结果分析可以看到,text1text2text3text4结果还是相对较好的,对于text5这种规则覆盖之外的场景,方法效果大大降低。
作者:KevinTao
知乎号:Kevin陶民泽
备注:转载请注明出处。
如发现错误,欢迎留言指正。
《笠翁对韵》第3集 王伟勇教授主讲 2017年2月22日 学生:向老师行鞠躬礼,老师好。 老师:同学早,请坐。 学生:谢谢老师。 老师:昨天回去有把一东韵一段、二段、三段都念一遍的请举手.
1900/1/1 0:00:00出品/Blockeye 文编/橘子馅儿 有人说,币圈仿佛就如一个娱乐圈,最不缺的,除了韭菜,便是各种瓜了.
1900/1/1 0:00:00有一天,来自另一个宇宙的一位物理学家通过某种我们未知的方式,悄悄地来到了地球上,她的任务是尽可能的了解我们宇宙中的一切.
1900/1/1 0:00:0012月19日,中国海洋大学与中国交通建设股份有限公司(简称“中国交建”)战略合作框架协议签约仪式在中国海洋大学崂山校区举行.
1900/1/1 0:00:00从自然货币产生起,距今已有几千年的历史。货币的出现与商品的交换紧密相连,是伴随商品交换的发展自然而然而产生的.
1900/1/1 0:00:00佛是佛法的创始人,他被称为SiddhārthaGautama,这个名字代表“觉悟者”,他是被超自然真理教化和感化的人.
1900/1/1 0:00:00