撰文:Tanya Malhotra
来源:Marktechpost
编译:DeFi 之道

图片来源:由无界版图AI工具生成
随着生成性人工智能在过去几个月的巨大成功,大型语言模型(LLM)正在不断改进。这些模型正在为一些值得注意的经济和社会转型做出贡献。OpenAI 开发的 ChatGPT 是一个自然语言处理模型,允许用户生成有意义的文本。不仅如此,它还可以回答问题,总结长段落,编写代码和电子邮件等。其他语言模型,如 Pathways 语言模型(PaLM)、Chinchilla 等,在模仿人类方面也有很好的表现。
元宇宙项目YouCoin宣布已部署至BNBChain:据官方消息,元宇宙项目YouCoin(UCON)宣布已成功部署至BNBChain,同时dApp开启首轮Earn+NFT,包括ETH等主流币质押服务,之后将陆续推出DAO、GameFi等更多系列生态。[2023/3/29 13:33:01]
大型语言模型使用强化学习(reinforcement learning,RL)来进行微调。强化学习是一种基于奖励系统的反馈驱动的机器学习方法。代理(agent)通过完成某些任务并观察这些行动的结果来学习在一个环境中的表现。代理在很好地完成一个任务后会得到积极的反馈,而完成地不好则会有相应的惩罚。像 ChatGPT 这样的 LLM 表现出的卓越性能都要归功于强化学习。
OpenAI正为ChatGPT添加插件支持,允许使用第三方服务:3月24日消息,OpenAI 宣布正在为 ChatGPT 添加对插件支持,插件是专门为以安全为核心原则的语言模型设计的工具,可帮助 ChatGPT 联网访问最新信息、运行计算或使用第三方服务。
OpenAI 已开放第一批 ChatGPT 插件名单,这批插件由 Expedia、FiscalNote、Instacart、KAYAK、Klarna、Milo、OpenTable、Shopify、Slack、Speak、Wolfram 和 Zapier 创建。OpenAI 表示,将开始把插件 Alpha 访问权限扩展到候补名单中的用户和开发人员。
检索插件允许ChatGPT搜索内容矢量数据库,并将最佳结果添加到 ChatGPT 会话中。这意味着它没有任何外部影响,主要风险是数据授权和隐私。[2023/3/24 13:23:50]
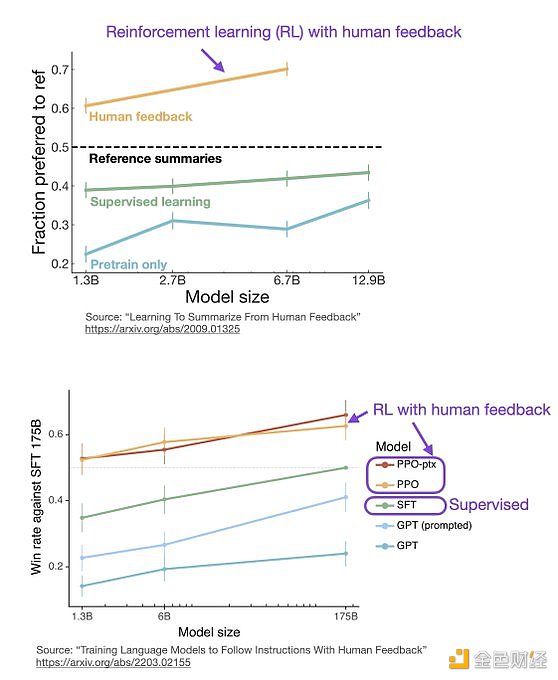
ChatGPT 使用来自人类反馈的强化学习(RLHF),通过最小化偏差对模型进行微调。但为什么不是监督学习(Supervised learning,SL)呢?一个基本的强化学习范式由用于训练模型的标签组成。但是为什么这些标签不能直接用于监督学习方法呢?人工智能和机器学习研究员 Sebastian Raschka 在他的推特上分享了一些原因,即为什么强化学习被用于微调而不是监督学习。
Partisia Blockchain和Insights Network合作推出区块链和MPC技术,并完成首次集成:4月22日消息,多方计算(MPC)多年来已有广泛的发展,为下一代Web3互联网提供了理想的基础设施。Partisia Blockchain基金会合伙人、教授兼首席密码学家Ivan Damgard表示:“MPC可以进行任何类型的私人计算。换句话说,MPC是一个完全分布式的加密计算机。这与零知识证明非常不同,零知识证明只有两个参与方,结果是二元的,即陈述是真是假不得而知。”
此类解决方案适用于任何类型的企业,包括供应链公司、SaaS(软件即服务)提供商、金融科技应用程序甚至社交媒体。例如,Partisia Blockchain和Insights Network合作推出的区块链和MPC技术,在社交媒体平台上进行了首次成功集成。
对于需要处理数百万甚至数十亿事务的平台,可扩展性是通过分片技术解决的。一个新的分片扩大了网络的容量,使Partisia区块链能够满足任意数量的TPS。例如,社交媒体提供商可以每天处理数十亿个流程,同时在用户隐私方面做好保护。
以用户隐私保护为中心的可扩展解决方案只是全局中的一部分。就Partisia Blockchain而言,先进的互操作性框架,模仿了复式簿记系统,使得任何人都可以轻松检测到任何欺诈行为。在客观欺诈的情况下,争议程序将会补偿损失。这种设置让不同的区块链网络可以有效地使用相同的术语,并且安全地传输数据。(福布斯)[2022/4/23 14:42:53]
动态 | Blockchain将整合BitPay的钱包支付系统:据coindesk消息,比特币钱包和区块链浏览器提供商区块链宣布与最大的比特币处理器BitPay合作。区块链将把BitPay的支付架构整合到它的钱包服务中。这项合作将允许区块链钱包用户在线或移动支付商户。[2019/8/24]
不使用监督学习的第一个原因是,它只预测等级,不会产生连贯的反应;该模型只是学习给与训练集相似的反应打上高分,即使它们是不连贯的。另一方面,RLHF 则被训练来估计产生反应的质量,而不仅仅是排名分数。
Sebastian Raschka 分享了使用监督学习将任务重新表述为一个受限的优化问题的想法。损失函数结合了输出文本损失和奖励分数项。这将使生成的响应和排名的质量更高。但这种方法只有在目标正确产生问题-答案对时才能成功。但是累积奖励对于实现用户和 ChatGPT 之间的连贯对话也是必要的,而监督学习无法提供这种奖励。
不选择 SL 的第三个原因是,它使用交叉熵来优化标记级的损失。虽然在文本段落的标记水平上,改变反应中的个别单词可能对整体损失只有很小的影响,但如果一个单词被否定,产生连贯性对话的复杂任务可能会完全改变上下文。因此,仅仅依靠 SL 是不够的,RLHF 对于考虑整个对话的背景和连贯性是必要的。
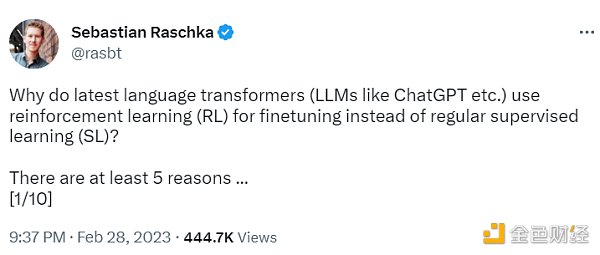
监督学习可以用来训练一个模型,但根据经验发现 RLHF 往往表现得更好。2022 年的一篇论文《从人类反馈中学习总结》显示,RLHF 比 SL 表现得更好。原因是 RLHF 考虑了连贯性对话的累积奖励,而 SL 由于其文本段落级的损失函数而未能很好做到这一点。
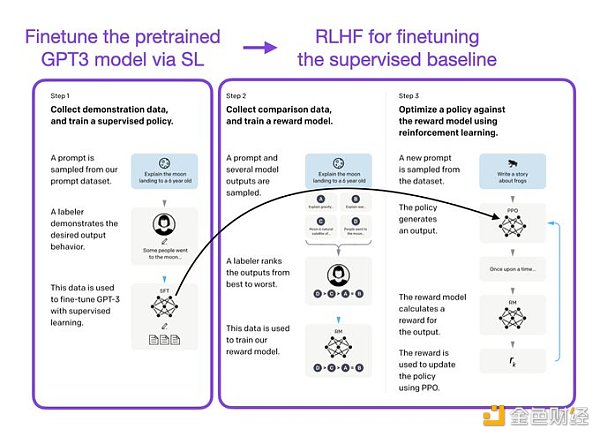
像 InstructGPT 和 ChatGPT 这样的 LLMs 同时使用监督学习和强化学习。这两者的结合对于实现最佳性能至关重要。在这些模型中,首先使用 SL 对模型进行微调,然后使用 RL 进一步更新。SL 阶段允许模型学习任务的基本结构和内容,而 RLHF 阶段则完善模型的反应以提高准确性。
DeFi之道
个人专栏
阅读更多
金色财经 善欧巴
金色早8点
Odaily星球日报
欧科云链
Arcane Labs
MarsBit
深潮TechFlow
BTCStudy
澎湃新闻
原文:《产品“摆拍”展示 文心一言露怯》 作者:文刀 3月16日,“文心一言”没有在问答环节 “翻车”,因为,百度创始人李彦宏在开发会现场展示的这个自然语言大模型产品,测试的过程和结果是提前录制好的.
1900/1/1 0:00:00原文标题:《The USDC Depeg Implications on DeFi: Two Paths Forward》 撰文:Igans 编译:Frank.
1900/1/1 0:00:00撰文:Karen,Foresight News作为 Web3 世界最重要的基础设施和庞大流量入口,加密钱包对于 Web3 大规模采用的重要性不言而喻.
1900/1/1 0:00:00导读:一家引领全世界的搜索引擎巨头,已经手握类ChatGPT技术两年,却被微软和OpenAI步步抢先,正在逐渐失去自己曾经制霸的领土。谷歌的故事,值得所有人深思。 最近,微软是喜讯连连.
1900/1/1 0:00:00撰文:0xLoki 最近在推上和 Space 上和很多朋友讨论了 LSD 杠杆挖矿的问题,主要的问题在于:杠杆 Staking 高收益的本质是什么?风险点在哪里?杠杆 Staking 的高收益是否可持续?关于杠杆 Staking 的合.
1900/1/1 0:00:00原文作者:Babywhale,Foresight News2020 年 3 月 12 日,受疫情影响,美股经历了自 1987 年「黑色星期一」以来最大的单日跌幅,触发了美股历史上第二次熔断.
1900/1/1 0:00:00