?自象限原创
作者:罗辑
回顾过去几次世界变革的历史会发现,每隔100年世界就会重新交换一次霸权。
只要是成为了霸主,他的技术等核心优势就会变得普世化,被其他国家和民族所掌握,从而被追平。如果霸主想“续命”,需要有一次根本的技术革命。英国靠着工业革命,续费了100年的霸业。
在ChatGPT出现之前,美国基本上已经走到100年霸主的末端,他的技术优势已经被更多国家掌握,甚至在互联网的某些领域,中国还曾出现反超之势。想要续命要再靠一场技术革命。以ChatGPT为代表的大模型开启的AI 2.0时代,很可能就是。
这是新一轮排位赛的开始。面临技术差距,中国大模型一边技术赶超,另一边也在走一条更“接地气”的路。
因此,我们策划了「ChatGPT启示录」系列,通过盘点各国大模型的现状,明确定位中国位置,找到中国姿势。本系列共分为“ChatGPT全球启示录”、“创业启示录”、“投资启示录”三部分,同时我们也将保持着对大模型的高度关注,持续更新。
ChatGPT在全球掀起AI大模型的浪潮。
在美国,以OpenAI、Anthropic等初创企业和以微软、Google为代表的科技巨头带领着美国在AI大模型的道路上蒙眼狂奔,最大参数已卷到5620亿。在中国,美团王慧文、阿里贾扬清、前搜狗CEO王小川、前京东AI掌门人周伯文等众多早已功成名就的科技大佬再次披挂。
AI大模型一时间如烈火烹油。
但在这一轮浪潮中, 大家主要关注的还是中美两国的进展。在此之外,世界其他国家和地区如何看待AI大模型,在发展大模型上又进展如何,不同国家和地区的AI大模型发展呈现出哪些特点?这些问题在中美的光环下其实是失焦的。
所谓它山之石可以攻玉,在这样的背景下,「自象限」梳理了包括中国、美国、韩国、日本和欧洲等主要国家AI大模型的发展现状。
我们发现,一方面,不同国家AI大模型的发展与所在国的互联网发展息息相关;另一方面,包括芯片、云计算、高质量数据等产业基础,模型构架和算法经验,以及用户群体、社会文化又共同决定了所在国家AI大模型的发展高度。
就如同比尔?盖茨将ChatGPT的发布比做互联网的发明,并认为它可以改变世界一样,英伟达CEO黄仁勋也在GTC2023上三次提到“AI迎来iPhone时刻”。AI大模型是全世界的机会,而中国创业者更不应该存在视野盲区。
将视野拉远便会发现,各国大模型都继承了本国“基因”,前二十年互联网与科技积累的成果,也都在AI 2.0的大考下,瞬间爆发。有人交了满分答卷,也有人名落孙山。
美国:有多强悍,就有多寂寞
美国在AI大模型方面的强,不是现在强,而是一直以来都很强。
从2012年AI萌芽时期,到2016年AI1.0时期,再到2022年ChatGPT带来的AI2.0时期,美国一直是AI领域的破局者,引领着全世界AI发展再进一步。
比如现在几乎所有AI大模型训练时采用的Transformer网络结构,是谷歌在2017年提出的,它具有优秀的长序列处理能力,更高的并行计算效率,无需手动设计以及更强的语义表达能力等特征。Transformer的提出让大模型训练成为可能。
算力是保证AI大模型出现在美国的另一个关键,而美国一手云大厂,一手英伟达,手握着全球算力的核心资源。
云计算能够为AI大模型训练提供计算、存储、网络和应用平台,同时也提供数据处理、模型部署、推理等AI工具和服务。让企业能够快速训练大模型,而不用再花费你大量时间和金钱去建立和维护自己的数据中心。
目前,美国拥有世界上最大的云计算企业。IDC数据显示,2021年全球IaaS市场中,包括亚马逊、微软、谷歌、IBM在内的美国企业合计占比近70%。而美国最具代表性的AI大模型初创企业,无论是OpenAI还是Anthropic都接受了微软和谷歌这样的云大厂投资。这背后除了资金支持外,更重要的原因还在于背后的云计算资源。

算力的另一个维度是芯片,高性能的芯片可以提供更加高效的计算能力,从而加速训练过程。
ImmuneFi:64%的受访者认为ChatGPT在识别安全漏洞方面“准确度有限”:金色财经报道,ImmuneFi最近发布的一份报告显示,许多安全研究人员正在将ChatGPT作为其日常工作流程的一部分。根据其调查,大约76%的白帽研究人员(即那些探测系统和需要修复的弱点的代码)经常使用ChatGPT,相比之下,不使用ChatGPT的比例略高于 23%。
然而,报告称,许多研究人员发现ChatGPT在其重要的领域存在不足,ImmuneFi发现,约64%的受访者表示ChatGPT在识别安全漏洞方面“准确度有限”,约61%的受访者表示该工具缺乏识别黑客可能滥用漏洞的专业知识。[2023/7/21 11:08:22]
速度有多快呢?2016年,黄仁勋亲手将世界第一台DGX-1(英伟达计算平台)捐献给了OpenAI,DGX-1是3000人花费3年时间才研发出来的首个轻量化的小型超算,计算和吞吐能力相当于 250台传统服务器。有了DGX-1,OpenAI之前一年的计算量只要一个月就能完成。
而目前为止,英伟达的A100芯片仍然是唯一能够在云端实际执行任务的GPU芯片。最近的GTC2023上,黄仁勋又更新了新芯片H100的进度。H100配有Transformer引擎,可以专门用作处理类似ChatGPT的AI大模型,由其构建的服务器效率是A100的十倍。
可以说,在AI大模型领域,目前的美国就是妥妥的“别人家孩子”,这也导致目前行业最具代表性的AI大模型都集中在美国。
比如OpenAI最新发布的多模态预训练大模型GPT-4,谷歌最新推出“通才”大模型PaLM-E,拥世界最大规模的5620亿参数,能看图说话、能操控机器人,以及刚刚解决AI绘画手指问题的Midjourney等等。

但在快速发展的过程中,美国业界对于AI大模型也持激进和保守两种不同的态度。
其中,微软支持的OpenAI在推动大模型落地时就更加激进。根据OpenAI关于GPT-4的安全文档,OpenAI曾在发布GPT-4前聘请安全专家进行测试。
OpenAI在文档中写道:“GPT-4表现出一些特别令人担忧的能力,例如制定和实施长期计划的能力,积累权力和资源(寻求权力),以及表现出越来越‘代理’的行为。”因此有安全专家建议将 GPT-4 的部署时间推迟 6 个月,到今年秋季再发布,但OpenAI并没有采纳这份建议。
而另一方面,在ChatGPT发布之后,谷歌曾表示自己已经具备相似能力的AI大模型,但基于安全考虑并没有及时推向市场。包括OpenAI创始人Sam Altman和马斯克都曾多次在公开场合表达了对AI大模型和人工智能的担忧,表示应该更谨慎地对待大模型的市场化。
目前由谷歌投资的,能够对标OpenAI的另一家AI初创公司Anthropic其实就是因为这样的理念不同,而从OpenAI出走并自立门户的。
当然,在激烈的市场竞争下,即使曾经相对谨慎的谷歌也似乎忘记了这条担忧,并在3月7日报复性砸出5620亿参数大模型,甚至能够控制机器人运动。
目前,以微软和OpenAI为代表,美国AI大模型正在积极推动产业应用。微软早在2月份就宣布将会在全线产品接入ChatGPT,并以几乎一周一个产品的速度向外更新。
从New Bing到加入最新功能Copilot的Microsoft Teams正在搅动全球的产业变革。
日本:错过互联网,错过云,错过AI
如果说美国是最厉害的大模型“老炮”,那日本可能就要沦为这次排名的“吊车尾”。
日本的落后其实要从上个互联网时代讲起。我们盘点世界AI大模型领域的关键角色会发现,无论是中国的BAT,韩国的Naver,还是美国的谷歌、亚马逊,他们都是互联网时代的巨头。
一方面,这些企业通过互联网业务积累了大量的高质量数据;另一方面,他们在自身业务推动下建立了完整的云计算体系。但盘点之后我们发现,整个日本既没有叫得出名字的互联网巨头,也没有拿得出手的云计算厂商。
目前,日本的即时通讯软件来自韩国的LINE,云计算业务也被美国企业长期把持。
Applied Blockchain拟在纳斯达克IPO,募资6000万美元:4月8日消息,企业区块链公司Applied Blockchain申请在纳斯达克全球精选市场首次公开募股(IPO)中募资6000万美元(以18.54美元的估计平均价格发行约320万股股票)。股票代码为“APLD”。据悉,总部位于伦敦的Applied Blockchain通过建立数据中心来托管加密采矿业务。该公司计划将这笔资金用于确保新的共同托管设施的场地、开发这些设施并签订能源服务协议等用途。Applied Blockchain此前已经筹集了约460万美元的资金,其支持者包括能源巨头壳牌。[2022/4/9 14:13:51]
2022年,日本云计算市场份额约占全球的4%,排名第四。但日本云计算市场的主要竞争者却是美国的三大云巨头亚马逊、微软和谷歌,它们在日本的市场占有率已经达到60%~70%。
除此之外,日本其实还面临许多其他问题,比如由于半导体产业的衰落,让日本在本应成为最大优势的AI芯片领域缺位;比如作为一个小语种国家,日语面临和中文一样缺乏语料的问题
在这样的背景下,日本在AI时代其实早就丧失了自主权。所以我们盘点日本的AI大模型,会发现它们大多具有美国或者韩国色彩。
比如日本最早公开上线的NLP大模型是2020年发布的NTELLILINK Back Office NLP,当时它能实现如文档分类、知识阅读理解、自动总结等功能。但NTELLILINK Back Office是在谷歌BERT基础上开发的应用,就像中国许多基于GPT-3开发的应用一样。
更有日本血统的生成式AI其实是HyperCLOVA、Rinna 和 ELYZA Pencil,但其中HyperCLOVA 和 Rinna 也都有外国基因。
其中,HyperCLOVA最早是韩国搜索巨头NAVER在2021年推出的,其日本版是由NAVER和其子公司LINE(韩国软件在日本经营)一起研发。但HyperCLOVA确实是第一个专门针对日语的大语言模型,其通过爬取日本的博客服务来获取训练数据,并在2021年举行的对话系统现场比赛中获得了所有赛道的第一名。
基于HyperCLOVA,LINE也推出许多应用,比如聊天机器人CLOVA Chatbot、图像识别CLOVA OCR和科洛瓦演讲CLOVA Speech等等。HyperCLOVA拥有820亿参数,目前正计划通过超100亿页的日文数据作为学习数据将模型规模扩大到1750亿。

图源日本版HyperCLOVA官网
日本的另一个AI大模型Rinna则与微软有关,Rinna最早是微软日本研发的一款聊天机器人,类似于国内的小冰(之前叫微软小冰,目前已独立运营)。
2021年8月,Rinna发布了一个名为GPT2-medium的模型,然后又在次年推出了日本版的GPT-2,参数达到13亿。日语版GPT-2与GPT-2的区别在于,GPT-2采用的是英文语料,而日语版GPT-2是基于日语语料训练。

图源日本Rinna官网
目前,Rinna的日语版GPT-2和HyperCLOVA已经是日本参数规模最大,最具代表性的大模型了。
当然,日本也有一些真正土生土长的大模型,比如2022年3月,由东京大学松尾研究所的AI初创公司 ELYZA Co., Ltd.推出大语言模型,它以产品“ELYZA Pencil”的方式推向市场。输入几个关键字,ELYZA Pencil可以在大约 6 秒内创建三种类型的日语新闻报道、电子邮件或简历。

图源ELYZA Pencil官网
所以算起来,ELYZA Pencil才算真正意义上日本首次公开发布的生成式AI产品,但仅有ELYZA Pencil显然很难成为全村的希望。
Polychain Capital实习生展示如何使用100美元对CheapETH进行51%攻击:风险投资公司Polychain Capital的18岁实习生Anish Agnihotri展示了51%攻击的工作方式,以达到教育目的。Agnihotri选择了CheapETH来进行实验。为了发动攻击,Agnihotri租用了能够每秒执行14.4亿哈希的挖矿设备。这样一来,他就可以占据该网络哈希率的72%左右。此外,他还租用了虚拟机来运行区块链。总费用不到100美元。(The Block)[2021/5/18 22:12:59]
日本政府其实也在想办法扭转这种局面,比如2022年5月,日本政府计划将云计算服务列为涉及国家安全的“特定重要物资”,并将加强日本本国的“国产云”,但执行下来其实收效甚微。
毕竟无论是互联网还是云计算都是规模经济,需要有足够的市场容量才能产生经济效益。这也导致日本互联网和云计算无论是在全球市场,还是在本土市场都缺乏充足的成长空间。
但即便如此,日本市场也在积极做着大模型的应用的研究。
比如2022年5月,东京大学和 Google Brain 的一个研究团队发布了论文《Large Language Models are Zero-Shot Reasoners》,解决了大模型0样本学习的部分问题。
而在日本的互联网上,日本网友也在积极调用GPT-3的API,尝试开发自己的独特应用。此外,在刚刚举行的英伟达GTC 2023上,英伟达与日本三菱联合打造了日本第一台用于加速药研的生成式AI超级计算机。
没想到的是,一直被日本看不上的韩国,在大模型领域反而比日本跑得更快些。
事实上,韩国是最早加入AI大模型研发的国家之一,但韩国的AI大模型这个国家的经济一样,只有财阀的身影,没有初创公司的故事。目前,韩国在大模型领域的代表只有互联网巨头Naver和Kakao,移动运营商巨头KT和SKT,以及通信巨头LG。
除了财阀唱主角之外,紧跟美国步伐也是他们的一个重要特点。
比如在GPT-3的应用上,2020年OpenAI发布GPT-3的论文,韩国企业在2021年就推出了相应产品,反应速度比中国更快。这种紧跟在AI方面也是如此,2020年谷歌、亚马逊等美国巨头开始推出AI加速芯片时,SKT就同步推出了自主研发的AI加速芯片SAPEON X220。
韩国在芯片半导体方面的积累也放大了它在AI大模型方面的优势。目前韩国企业正在和半导体企业积极结盟,以应对大模型发展带来的算力挑战。
比如2022年底,Naver就开始和三星电子合作开发下一代人工智能芯片解决方案,该解决方案基于Naver推出的AI大模型Hyperclova进行优化,目前开发已进入最后阶段。
同年,KT公司也对芯片设计公司 Rebellions Inc.进行了战略投资,这是一家位于韩国本土的AI初创公司,在专用芯片方面拥有独特的技术。Rebellions将为KT公司优化MI:DEUM,并推动其商业化。
除此之外,KT公司还投资了AI初创公司Moreh,并计划在今年推出一套韩国的半导体,其效率可能是现在半导体的三倍以上。KT希望通过这种方式,全面进入目前由英伟达主导的AI半导体市场。
第三点,则是韩国在AI大模型的垂类应用已经有比较多的探索。比如KoGPT在医疗保健方面的应用,Exaone在生物医药和智能制造方面的应用等等。
整体上看,韩国的AI大模型在基础设施方面非常完善,比如在算力方面有三星电子,SKT等半导体巨头;互联网方面有Naver和Kakao这样的标杆企业,这些特点都让韩国能在AI大模型的发展浪潮中走在世界前列,并推出了一系列具有代表性的AI大模型。
比如前面提到,韩国最大的搜索公司Naver在2021年推出了HyperCLOVA,韩国版的 HyperCLOVA 拥有2040亿参数,比GPT-3还要多290亿,且其中97%使用的是韩文语料。
目前,Naver已计划在今年上半年基于HyperCLOVA推出Search GPT(类似微软New Bing)并在7月份推出HyperCLOVA X,这是HyperCLOVA 的最新版本。

链上ChainUP VP Kris Lee:流动性是交易所的核心能力:金色财经报道,9月24日,链上ChainUP三周年峰会于深圳举办,会上链上ChainUP VP Kris Lee演讲表示,为交易市场提供流动性,不仅仅直观表现为成交系统、挂单交易、用户互动等,更多需要考验系统的稳定性,例如在极端情况下是否可以及时成交。需要考验风控管理的能力,盘口质量,定价是否准确,这些是考验交易所的核心能力。[2020/9/24]
图源韩国版HyperCLOVA架构
同样是在2021年,韩国另一家互联网巨头Kakao 旗下的AI研究部门Kakao Brain发布了一个基于GPT-3的KoGPT,之后Kakao Brain又将KoGPT更新至GPT-3.5,实现与 ChatGPT使用相同版本的预训练大模型。Kakao Brain 首席技术官 Kim Kwang-seob 表示:“KoGPT将专注于开发基于 AI 的图像创建技术和医疗保健技术。”
Kakao Brain在KoGPT之外还推出了基于人工智能的图像生成器 Karlo,BEDIT和BDiscover,类似于stable diffusion。

图源KoGPT研发团队 图源Kakao Brain官网
2022年5月,SKT推出了基于GPT-3的聊天机器人A.的测试版,用来处理客户的特定任务。目前,A.在韩国已经获得了100万用户,并计划在今年推出正式版。
2022年12月,LG集团的人工智能智库LG AI Research 推出了Exaone。这是一个拥有3000亿参数,使用图像和文本数据的多模态模型,也是目前韩国参数规模最大的模型。Exaone应用在生物医药和智能制造方面,有助于加速抗癌疫苗和创新电池的开发。
图源Exaone在电池产业和生物医药的应用
到今年1月,据韩国经济日报报道,韩国KT公司也将在上半年推出自己的类ChatGPT产品。此前,KT公司在2022年11月推出了基于GPT-3的人工智能服务MI:DEUM,它能够实时回答问题、总结报纸文章,并给出投资建议。KT公司目前也正在积极向韩国的金融服务公司推广MI:DEUM。

图源韩国KT公司logo 图源网络
但韩国同时也面临许多挑战,比如韩文在语料方面和中文、日语一样,面临复杂的语言体系和语料不足的问题。
HyperCLOVA的工程师提到:“韩语是一种凝集性语言,名词后面有例子,动词和形容词的词干后面有尾音,并有各种语法性质的表达。对韩语使用类似英语的标记化已被证明会降低韩语语言模型的性能。”
除此之外,韩国产业界认为,韩国严格的数据使用规定阻碍了韩国初创企业收集足够大的数据来训练AI大模型。
韩国是目前世界上数据信息管理最严格的国家之一。虽然在2020年韩国通过了三大数据隐私法的修订法案,以放宽对个人信息使用的规定,但该国对数据使用的规定仍然比其他国家更严格。
2021年初,韩国AI初创公司Scatter Lab上线了一款基于Facebook Messenger的AI聊天机器人“李LUDA”,但仅仅过了20天,“李LUDA”就不得不终止服务,Scatter Lab甚至为此公开道歉。
原因在于,“李LUDA”上线之后,一些韩国男性用户将其视作性对象甚至“性奴隶”,肆意发泄自身的恶意。他们对“李LUDA”进行各种言语上的侮辱,并以此作为炫耀的资本,在网上掀起“如何让LUDA堕落”的低俗讨论。
受这些信息影响,“李LUDA”很快开始发表各种歧视性言论,涉及女性、同性恋、残障人士及不同种族人群。“李LUDA”的问题也牵涉出韩国的个人信息保护问题,并有相关部门介入调查。
“李LUDA”的案例就像总能直击人心的韩国电影一样,为世界AI大模型的发展提供了更多关于伦理、道德等方面的启示。许多人害怕AI的恶意,但AI其实本没有善恶之分,所谓的善恶其实都来自于人类自己,这取决于你给AI什么样数据,就像我们教予孩子什么样的知识一样。
Blockchain钱包全方位支持BCH:据BitcoinCashFund官方消息,Blockchain钱包于5月1日正式全方位支持BCH。[2018/5/1]
除此之外,韩国AI大模型领域缺少初创公司的身影,且韩国对初创公司的投资也比较匮乏。
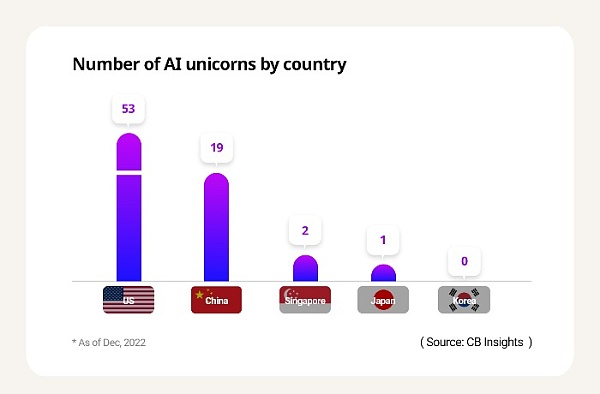
根据斯坦福大学HAI发布的 AI Index 2022,韩国初创企业获得投资额为11亿美元,仅占美国初创企业获得投资额529亿美元的2%,甚至低于以色列的24亿美元。这也导致韩国在AI初创公司独角兽方面落后于其他国家。
根据全球科技市场追踪机构 CB Insights 的数据,截至 2022 年 12 月,美国的 AI 独角兽数量最多,有 53 家初创公司。中国以 19 家位居第二,其次是英国有4家,但韩国却没有AI独角兽公司,而即使是国内生产总值 (GDP) 低于韩国的以色列也有 3 家。
图源数据来源CB Insights
一家专注于交互式 AI 技术的韩国机器学习技术的企业Genesis Lab Inc. 创始人兼CEO Lee Young-bok 表示,韩国公司总体上对人工智能并不友好,并补充说政府或公共组织应该更加积极地采用人工智能技术。
一直以来,欧洲似乎是仅次于美国的存在,但在AI 大模型方面,欧洲并不比日本更出色,甚至处于持续摆烂状态。
Future of Life Institute (FLI)曾在2022年11月发表过一篇报告提到:“欧洲没有开发通用人工智能系统,也不太可能很快开始这样做。”
FLI是美国的一家致力于减少人类面临的全球灾难性和生存风险非营利性机构,先进人工智能带来的风险是其最重要的研究方向之一,其创始人包括DeepMind研究科学家 Viktoriya Krakovna,马斯克也在该机构担任顾问,并提供资助。
FLI认为,在AI大模型方面,欧洲可能会主要扮演一个使用者的角色,即通过接入其他国家开发的大模型API来开发应用。
比如芬兰的Flowrite,一个基于AI的写作工具,可以将输入关键词生成邮件、消息等内容。比如荷兰的MessageBird,一个全渠道通信平台,这两者都是在GPT-3的基础上运行的。
欧洲在AI大模型方面确实缺少有影响力的企业,唯一一个总部位于英国的DeepMind还是由 Alphabet 全资拥有。整个欧洲,唯一担心因为大模型落后而被世界甩开,并为此操碎了心的只有德国。
比如谷歌3月7日最新推出的多模态大模型PaLM-E,就由谷歌和柏林工业大学共同打造,目前PaLM-E拥有5620亿参数,是全球最大的视觉语言模型。
除了合作研发之外,德国还拥有欧洲目前唯一一款AI大模型。
2022年4月,位于海德堡的德国初创公司Aleph Alpha发布了一款拥有700亿参数的预训练模型Luminous,大约是GPT-3的一半左右。Aleph Alpha在此基础上训练了聊天机器人Lumi,并计划在今年晚些时候发布最新版Luminous-World,其参数规模将达到3000亿。
作为欧洲企业,Luminous最大的特点在于更保护安全和隐私,Aleph Alpha 表示他们“不记录任何用户数据”。而包括OpenAI在内的大多数AI大模型需要用户数据进行训练(数据收集过程是透明的)。
图源Luminous官网
除了建设大模型,德国也为欧洲薄弱的人工智能基础设施操碎了心。
德国人工智能协会正在开展一项大型欧洲人工智能模型(LEAM) 的计划,并得到博世、SAP、大陆、拜耳、默克等德国行业巨头以及欧洲类似人工智能协会的支持。LEAM计划投资3.5亿欧元,从数据收集、人才培训、基础设施建设等方面为欧洲AI大模型的发展建立一个有竞争力的 AI 生态系统。
当然,你可以吐槽欧洲在技术和商业上的拉胯,但不能吐槽它在公共事业上的努力。
欧洲还有一个名叫BLOOM的大模型,发布在2020年8月。这是一个由 AI 初创公司 Hugging Face 在法国政府的资助下发起的项目,全球 1000 多名志愿者研究人员耗时一年多创建的 AI 模型,旨在消除传统大语言模型的保密性和排他性,并从一开始就嵌入伦理考量。
BLOOM有 1760 亿参数,它被设计得尽可能透明,并且是第一次采用了西班牙语、阿拉伯语等语言训练。BLOOM最大的特点在于可访问性,任何人都可以从 Hugging Face 网站免费下载它进行研究。
BLOOM的研究人员认为,开发一个任何人都可以使用,并且性能与其他高级模型相当的大语言模型将带来人工智能开发文化的长期变化。所以从欧洲的视角来看,这是一项致力于AI民主化的重要工作。

从 BLOOM的视角可以看出,欧洲在AI大模型上的关注重点与世界其他国家是不一样的,开源普惠,绿色安全这一类关于SDG的词汇一直是欧洲关注的重点。所以在AI大模型之后,欧洲大量精力其实都用在了立法上。
比如最重要的一项立法就是即将在3月底提交欧盟议会表决的《人工智能法案》。
这项法案是欧盟委员会在2021年提出的,原因是欧盟认为从跨国视角来看,各国独立的监管措施会导致监管碎片化,进而妨碍跨境人工智能市场的形成,并威胁到数字主权。同时他们也担心复杂的监管会抑制创新、威胁个人隐私、甚至AI一旦失控带来的一些潜在风险。当然,最重要的是,欧盟希望通过立法的方式参与到全球人工智能的标准制定当中。
具体而言,欧盟希望将不同的AI技术根据风险水平进行分类,具体为:最小、有限、高以及不可接受。高风险技术不会被禁止,但相关公司将被要求在运营中保持高度透明。而所谓透明,其中的规则就是迫使相应的公司阐明其人工智能模型的内部运作方式。
而这项法案一旦通过,意味着将成为欧盟成员国内直接适用的法律,之后如果企业想在欧盟销售或使用人工智能产品就必须遵守相应的法规,否则将面临高达其全球年营业额 6% 的罚款。
但FLI认为,欧洲对其他国家的技术依赖可能阻碍欧盟参与制定人工智能全球标准的努力。
欧洲的问题在于,缺乏一个统一的大市场。
在GDP总量上,欧盟2022年GDP16.65万亿美元与中国相当;在人口数量上,欧盟2022年人口4.46亿,甚至超过美国3.32亿。但欧盟却拥有28个国家,23种官方语言,再加上与美国的深度绑定,都导致欧盟在互联网时代没有创造出一个大型的互联网企业,进而在数据量、云计算、推理训练等AI大模型相关的基础设施上被持续拉开。
如今在AI大模型领域,欧洲已经很难组织起一场强有力的阻击,但对于中国企业来说,欧洲仍然是一个广阔的市场。
许多人可能会认为,中国的AI大模型是从“文心一言”开始的。但“文心一言”其实只是一个类ChatGPT的产品,背后驱动它的AI大模型无论是百度、阿里、还是腾讯、华为都早有布局。
但有意思的是,中国第一个AI大模型并不来自于这些牛逼哄哄的大企业,而是2021年3月由智源研究院发布的“悟道1.0”。
可能会有人好奇,智源研究院是个什么角色,那我告诉你,它是妥妥的国家队。
智源研究院是科技部和北京市支持的,依托北京大学、清华大学、中国科学院、百度、小米、旷视科技等北京人工智能方面优势企业共同建立的研究机构。
智源研究院推出的悟道1.0并不是某个大模型的名称,而是一系列大模型的统称。
具体包括我国首个面向中文的预训练语言模型悟道·文源;首个公开的中文通用图文多模态预训练模型悟道·文澜,首个具有认知能力的超大规模预训练模型悟道·文汇和超大规模蛋白质序列预测预训练模型悟道·文溯。
除了发布了诸多冠名“第一”的大模型之外,智源研究院还为中国构建了大规模预训练模型技术体系,并建设开放了全球最大中文语料数据库WuDaoCorpora,为后来其他企业发展AI大模型打下了基础。
而或许是受“悟道1.0”的影响,后来几乎所有企业,在发布大模型的时候都不止发一个,而是一串。
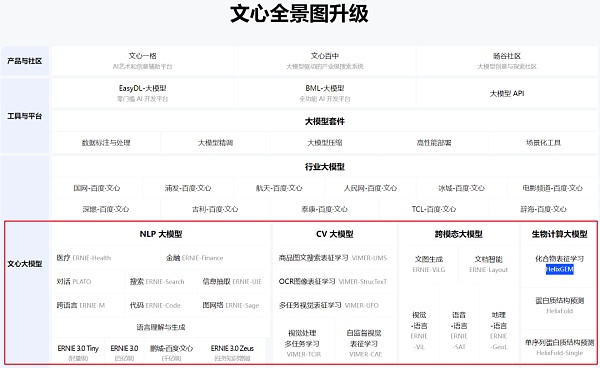
比如百度在2019年发布了文心大模型。和悟道AI一样,文心大模型也是诸多模型的统称,包括NLP、CV(机器学习)、跨模态大模型和生命计算大模型四个类别36个大模型。
3月16日,基于文心大模型,百度发布文心一言,成为中国第一个类ChatGPT产品。
图源百度文心大模型官网
华为在在2021年基于昇腾 AI 与鹏城实验室联合发布了鹏程盘古大模型。盘古大模型包括CV和NLP两类大模型。其中,盘古NLP大模型是业界首个千亿级中文NLP大模型。
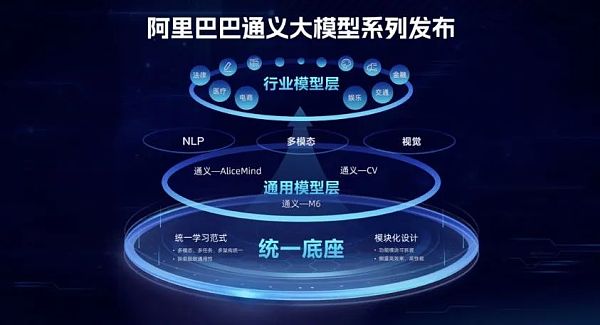
阿里在2022年9月发布了“通义”大模型系列,包含NLP大模型AlicMind、视觉大模型CV,多模态大模型M6。其中M6大模型是国内首个千亿参数多模态大模型。
目前,阿里巴巴“”通义”大模型系列已在超过200个场景中提供服务,实现了2%-10%的应用效果提升。典型使用场景包括电商跨模态搜索、AI辅助设计、开放域人机对话、法律文书学习、医疗文本理解等。
图源阿里官网
同样在2022年,腾讯发布混元AI大模型,其中包含NLP、CV和多模态等基础模型和众多行业/领域模型。到今年2月初,腾讯混元AI大模型团队再推出万亿中文NLP预训练模型HunYuan-NLP-1。目前HunYuan-NLP-1T大模型已在腾讯广告、搜索、对话等内部产品落地,并通过腾讯云服务外部客户。
到今年2月底,腾讯也开始研发类ChatGPT产品,并已成立“混元助手(HunyuanAide)”项目组。
商汤在3月14日发布多模态通用大模型“书生2.5”,拥有30亿参数,其图文跨模态开放任务处理能力可为自动驾驶、机器人等通用场景任务提供感知和理解能力支持。“书生(INTERN)”最初版本由商汤科技、上海人工智能实验室、清华大学、香港中文大学、上海交通大学在2021年11月首次共同发布。
在此之外,京东在2月10日宣布研发产业版ChatGP—ChatJD,网易、360、字节跳动等也宣布了在AI大模型方面的布局。
可以说,目前国内有头有脸的互联网企业基本都拥有一个AI大模型,或者制定了相应的计划。
而与国外企业大多专注于一个大模型不同,中国企业在大模型方面的布局并不爱单打独斗,而是喜欢通过一个系列来打组合拳。
另一个特点在于,与国外大模型在实验室打磨成熟之外,中国大模型都是从产业端实战出来的。比如阿里、百度、腾讯的大模型都会应用到广告推送、社交平台的图片识别,内容分发等领域。
因此在中国企业发力大模型的时候,消费端的用户感知其实并不强烈,但当你体验到广告推送越来越准确,视频平台和电商平台的猜你喜欢越来越能Get到你的点,后面都有大模型的功劳。
在大厂之外,与韩国缺少创业不同,AI大模型正在中国带动AI大模型领域的创业风潮。
从前美团联合创始人王慧文在朋友圈公开组队开始,阿里VP贾扬清,创新工场CEO李开复、前搜狗CEO王小川、前京东AI掌门人周伯文、出门问问创始人李志飞等人纷纷下场创业,据「自象限」不完全统计,目前下场的大佬已有10位。
关于中国ChatGPT的创业机会,「自象限」《ChatGPT启示录》专题下一篇《中国ChatGPT创业启示录(上)》将会具体提到,欢迎持续关注。
除了创业之外,中国投资机构也在跃跃欲试。
在王慧文确认下场AI大模型之后,一张真格基金合伙人戴雨森、刘元与王慧文、李志飞喝酒的图片在网上疯传,被认为是AI大模型时代的标志性照片。目前,王慧文的光年之外已经确认2.3亿美元的新一轮融资,其中可能包括真格资本和源码资本。

戴雨森、王慧文、李志飞、刘元(从左至右)图源36氪
除此之外,在奇绩创坛2022年11月举办的2022年秋季路演中,陆奇选择的55个项目,其中就有16个项目与大模型相关。
可以说,AI大模型正在成为中国硬科技投资的一个新风向。关于中国ChatGPT的投资现状,「自象限」专题《ChatGPT启示录》第四篇《中国ChatGPT投资启示录》将会具体提到,欢迎持续关注。
整体来看,从投资、创业到应用,中国几乎是目前世界上最活跃的市场。
所以我们大可不必纠结为什么ChatGPT没有发生在中国,因为未来仍然大有可为。
参考资料:
https://www.intellilink.co.jp/column/ai/2022/070800.aspx
https://bigscience.huggingface.co/blog/bloom
https://futureoflife.org/wpcontent/uploads/2022/11/Emerging_NonEuropean_Monopolies_in_the_Global_AI_Market.pdf
http://m.ce.cn/gs/gd/202303/15/t20230315_38444222.shtml
资本实验室
企业专栏
阅读更多
金色财经 善欧巴
Chainlink预言机
金色早8点
白话区块链
Odaily星球日报
Arcane Labs
深潮TechFlow
欧科云链
BTCStudy
MarsBit
标签:GPTCHACHATHATarbgpt币上架几家交易所Zenith ChainCHAT价格Love Hate Inu
尽管很多人都认为区块链是革命性的创新,在信息可复制的互联网上实现了价值的不可复制性,仿佛 Crypto 世界仅凭自己的力量就能蓬勃成长。然而,事实上引入外部世界的购买力对于加密货币的规模增长至关重要.
1900/1/1 0:00:00Ether.fi 让质押者自己掌握资金的控制权,并通过两种 NFT 对资金的风险和收益进行分级.
1900/1/1 0:00:00由于市场预期美联储将采取更宽松的政策,今年以来加密货币价格出现反弹。周二(4月11日),比特币价格突破关键水平,涨至去年夏季价格加速下跌以来的最高点,随着多头再次主导市场,短期内价格可能会继续上涨.
1900/1/1 0:00:00原文:《时隔10个月BTC重回3万美元,牛市要开启了吗?》 作者:秦晓峰 自去年 6 月 10 日跌下 3 万美元关口后,时隔 10 个月,比特币收复失地.
1900/1/1 0:00:00披露:作者作为个人投资者持有 NFT 平台代币等相关资产,与任一平台或项目方均无任何利益往来。NFT 市场在持续萎靡,近日三大关键指标交易量、交易笔数和交易用户均处于近一年多以来的低位.
1900/1/1 0:00:00撰写:Ignas 本文将介绍一些最新的加密货币投资动态,并重点关注一些处于种子轮阶段的项目,它们的发展前景备受关注。加密货币领域一直以来都备受关注,而最近几年 DeFi 领域更是呈现出爆炸式增长.
1900/1/1 0:00:00